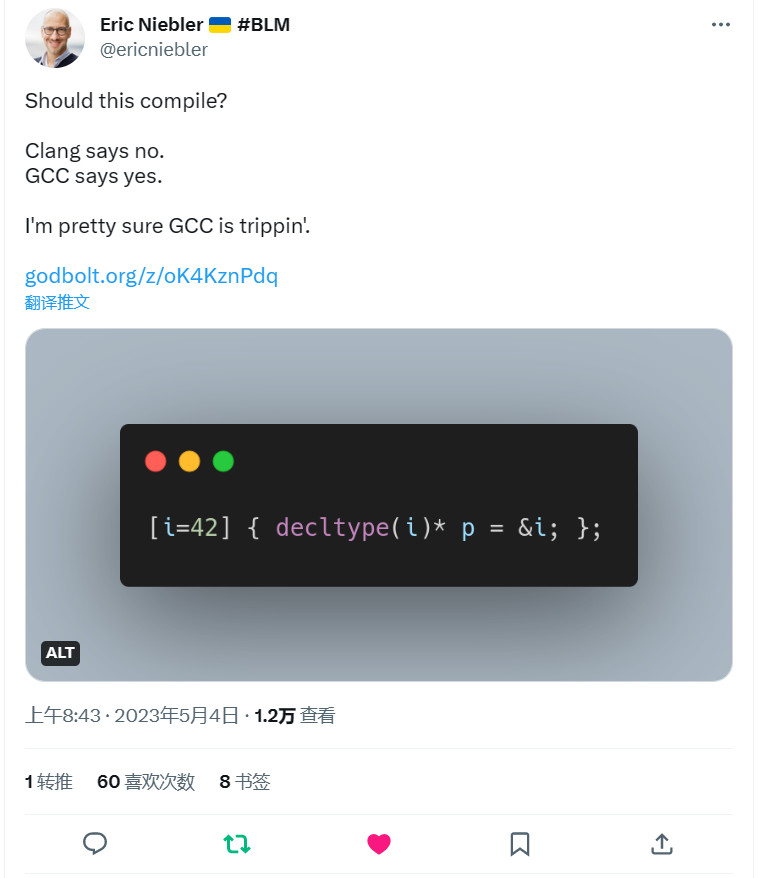
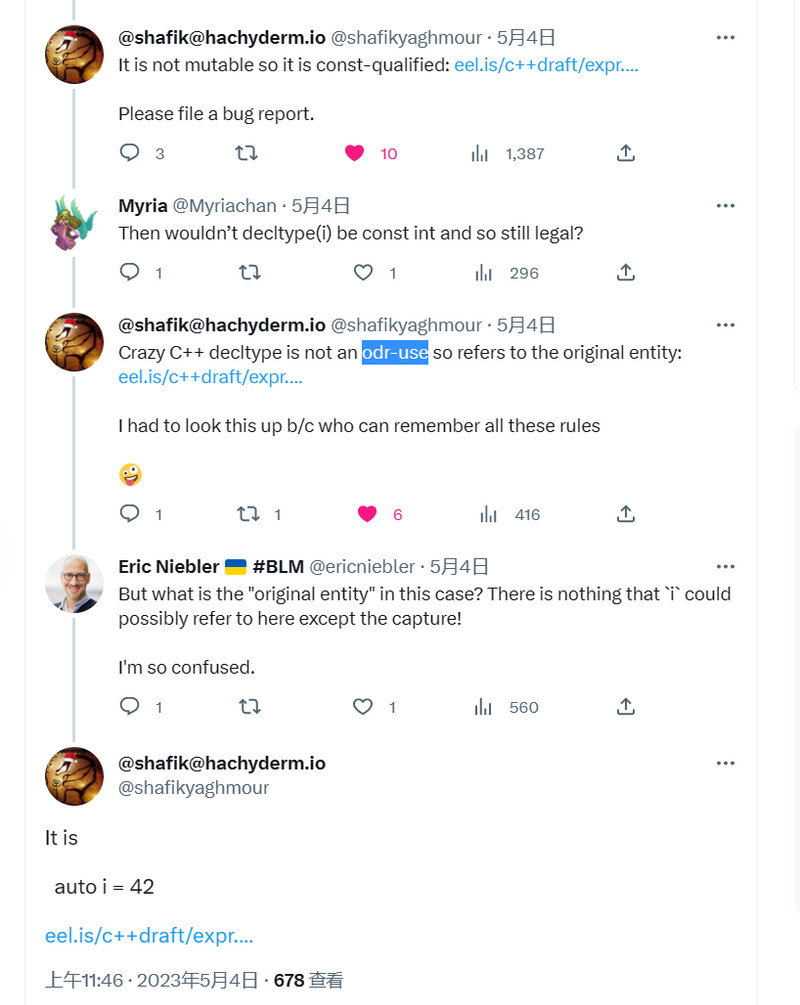
分享之前想到过的一个问题,不过不是具体编译器的实现,而是标准的缺陷:
enum E {
ee, ee
};
以上代码能否编译通过呢?不出乎意料地,gcc和clang都不可以。
enumtest.cpp:3:2: error: redefinition of enumerator 'A'
A,
^
enumtest.cpp:2:2: note: previous definition is here
A,
^
1 error generated.
出乎意料的是,C++标准中,没有任何一条规则阻止重复定义枚举值。理论上这个代码是符合C++标准的(但是不符合C标准)。实际上这个是C++标准的一个 defect:
https://blog.miigon.net/posts/cpp-core-language-issue-for-enum-const-redefinition/
https://www.open-std.org/jtc1/sc22/wg21/docs/cwg_defects.html#2530
一句话概括:从声明角度,两次ee的声明,对应的是同一个实体,不会产生声明冲突。而从定义的角度,ODR并没有限制 enumerator 的重定义(只限制了 enumeration type 本身的重定义,也就是上述代码中的E)
No translation unit shall contain more than one definition of any variable, function, class type, enumeration type, template, default argument for a parameter (for a function in a given scope), or default template argument.
6.3 [basic.def.odr]
对比C语言对这一问题的规定:
From the draft of C99, Section 6.7:
6.7.5. A declaration specifies the interpretation and attributes of a set of identifiers. A definition of an identifier is a declaration for that identifier that:
— for an object, causes storage to be reserved for that object;
— for a function, includes the function body;
— for an enumeration constant or typedef name, is the (only) declaration of the identifier.
在研究这个问题的过程中,读了一部分C++标准关于类型定义和推导的规定。对C++标准的风格有浓厚的这种感觉:间接层好多。
举一个抽象的例子,C里面可能是:A概念 =不满足某一规定条件=> 程序ill-formed。
在C++里可能是:A概念 =满足条件1=> B概念 =满足条件2=> C概念 =不满足条件3,且不是概念D=> 程序ill-formed
这样。
随着语言特性数量的增长,语言标准复杂度的增长是O(n2)趋势,因为任何一个新特性都潜在可能于任何一个已有特性相交互。而尝试将这些复杂的规则全部覆盖,要么依靠粗暴的列举(像ODR rule风格,显而易见需要列举 n2 条,不现实),要么引入“中间层”概念,尝试在这些概念间,用一套分叉的规则,把所有可能的交互都规定清楚。(会引入很多中间概念,理解压力增大,更容易出现疏忽而产生defect)
我个人觉得Golang的标准属于是语言设计的一个好例子,因为Golang设计之初的目标之一就是有意地对抗标准和语言特性的墒增和复杂度爆炸。语言的设计(从而标准的设计)都趋向简介的前提下,依然保证了比较充足的表达能力(即使有一些比较questionable的设计选择,比如范型的设计,比如循环变量引用问题)。这使得任何程序以及任何编译器的合法性检验变得简单,并且任何人都可以比较轻松地通过阅读标准来检验某一个语言特性假设的存在/不存在或准确/不准确。
我一直认为C和C++(以及Golang和Rust)体现了两种不同的解决问题的思想。
C(或Golang)解决问题的方法是:让使用者写更多的代码。语言只提供了最基本的工具和要素(指针等),更高阶的特性和机制,都要开发者在代码中自己实现。从而保持了语言设计的相对简洁,降低了学习门槛以及陌生代码的阅读难度。(即使偶尔有时候一些比较高阶的特性,在代码中实现的话会比较hack)
C++(或Rust)解决问题的方法是:语言添加新的特性。从而使得代码比较简短(但不一定简洁易读)。阅读代码所需要的背景知识明显上升。语言特性的数量明显上升,语言本身的复杂度平方级别增长。边界情况更多也就更常出现编译器不符合标准的情况。程序员编码量下降但是代码理解难度上升,潜在的更多的隐式规定。容易出现模版元编程这种黑魔法(arguably 特性滥用)。
从个人来说,更认同第一种思想。一个简单的功能集,加上良好的宏支持以及适时使用代码生成器来减轻需要写更多代码的影响,而换来的是更大的信心“通过看代码,我就能相信我的程序是正确的”而不需要担心在一两千页的标准中的某一页的某一行有一条小规则没有理解而写出错误的代码。代码的可读和可理解个人认为比代码的短或“能用最少的按键次数做最多的事情”更重要,后者是反维护的,从而可以说是反生产力的。
前面提到的,C++模版元编程,其实本质上是为了实现一个“在编译期进行自定义计算”或者“对编译器进行编程”的能力。与其利用各种复杂的rule/hack/side effect去扭曲特性做他们或许本不是设计目标的事情,并且不断添加新的特性/规则/特例来尝试扩充这种frankenstein式的能力集,还不如提供一个最简单的“编译期执行程序”的能力(codegen),并提供良好的语言解析支持(go的parser)。
从这个角度上,我有点担心 Rust 长期发展下去会不会也发生像 C++ 一样的包袱积累和复杂度爆炸。因为现在有一点点感觉他是后一种解决问题的思想。