前言
刚投简历,要准备下面试了,顺便复习下以前搞过的东西,然后补一下坑。
(来个dalao捞下我8 x_x)
然后,这篇水贴会先介绍一下GDB的基本用法,然后会介绍一些偏PWN的用法(毕竟我是搞PWN的),最后记录一下一些骚操作。
(另:想到什么就水什么了,想不到的就算了)
介绍篇
所谓调试器就是用来调试程序的工具(废话)。比如有一天我写了个程序发现运行的时候突然挂了,从代码上找不出原因/代码太长根本就不想去找,这个时候就需要用到调试器来定位程序出问题的地方以及原因。
而GDB是Linux上开源且最强大(毫无疑问的是“最”)C/C++的调试器,虽然其他语言写的程序通过某些方法都可以用GDB来调试(但是我没用过就不写了)。另外说一下,Windows下使用GDB的话可能会出现一些神奇的情况,而且Windows下也有其他别的调试器(IDA、Ollydbg、x64/x32dbg等),所以也很少用GDB了。
然后简单介绍一下调试器的原理(不知道这个也不会影响使用的),首先要介绍一下“int 3”这条指令,int 3叫做断点指令,程序运行时遇到int 3指令后就会停下来(暂停),这时调试器就可以通过执行自己的代码来调试程序了。上面说的是把int 3指令写在代码里面的情况,而调试器其实是动态替换int 3指令的,由于程序运行都要挂到内存上,所以调试器就有机会改指令了,在运行到调试器的断点或者单步执行时调试器会把下一条指令替换成int 3,继续执行时就替换回去。(大概是这样吧,没深入研究)
安装篇
通常Linux的包管理器都包含GDB,直接用包管理器安装就可以了,比如ubuntu的话就是:
sudo apt install gdb
但是我建议的话是安装带Python的GDB,人生苦短嘛。有的包管理工具是会有带Python的GDB的,大概叫“gdb-python”之类的,如果没有的话也可以像我一样编译安装,参考:https://www.jianshu.com/p/9b969c961f42
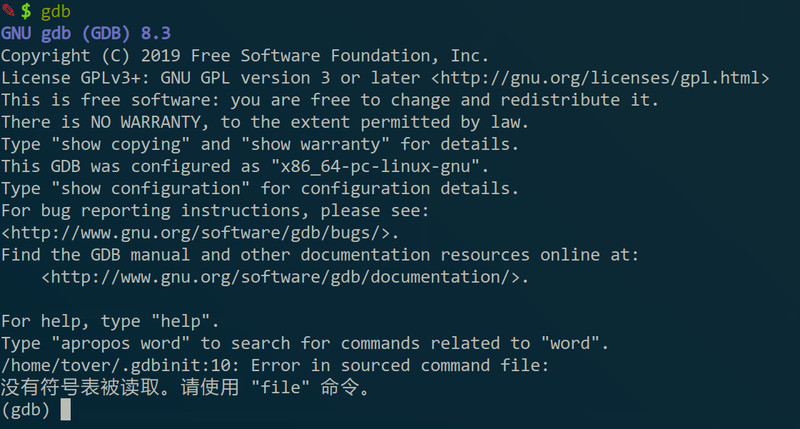
安装好后命令行输入“gdb”就可以运行,像这样:
初阶用法
首先是一些入门的用法,在这之前要复习一下GCC编译程序的方法。
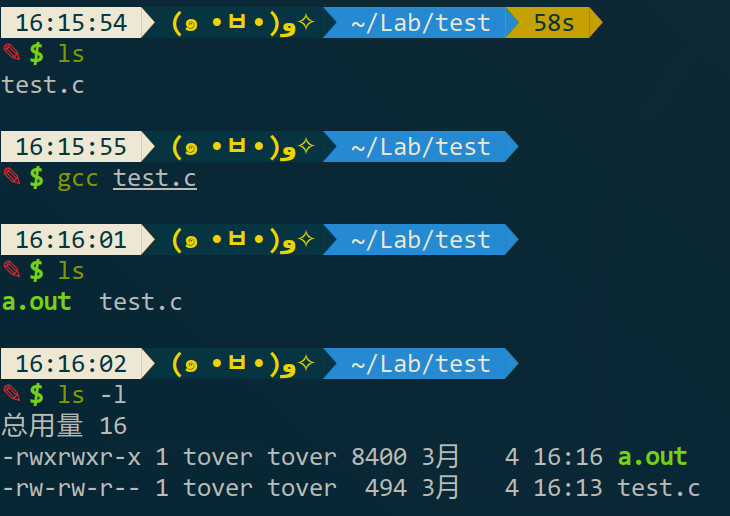
比如我有一份叫test.c的代码,要把代码编译成可执行文件的话执行:
gcc test.c
然后目录下就会有一个叫a.out的可执行文件:
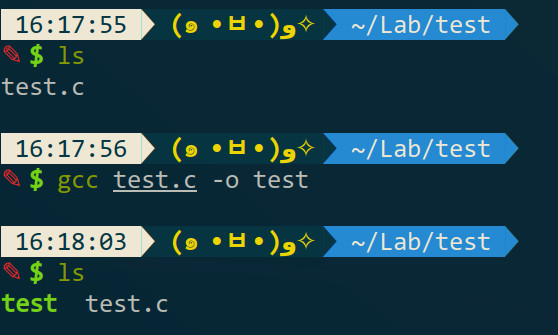
如果想改成别的名字的话可以这样编,比如程序编译好后我想把它叫test:
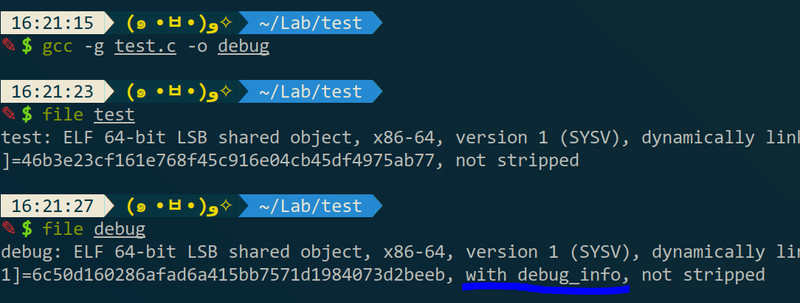
运行时直接输程序名字回车就好。但是如果要方便调试的话在编译还要加写东西,要加个“-g”参数,目的是给程序加个叫debug_info的东西(可以看出加了“-g”后显示是“with debug_info”):
做完这些准备后就可以GDB调试了,调试方法是命令行”gdb 程序名“回车:
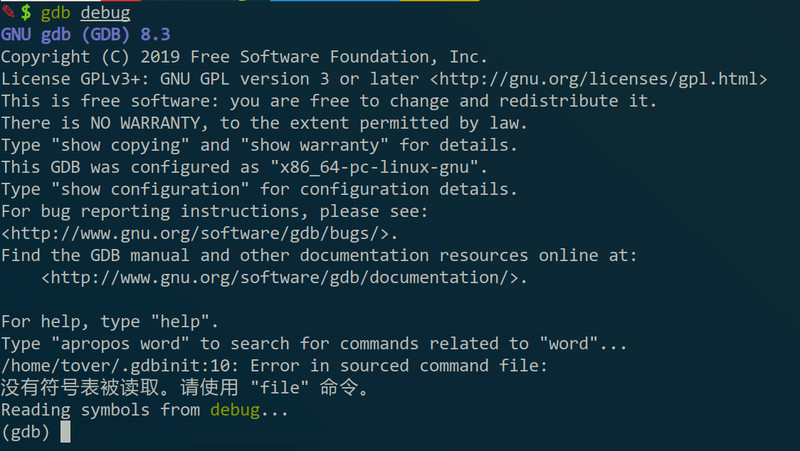
嗯跟上面的好像没什么区别,但其实是已经指定了要调试的程序,而且把一些信息也读进去了,比如有个“Reading symbols from debug”说的就是“debug_info”。在继续说之前先说一下test.c是什么(其实是当时出给19图灵班的一道题,但忘了没给源码的话有debug_info也没用所以就没做成,但后面会介绍一些其实没源码也可以解出来的)。运行后程序会要求猜一个数,如果猜对了的话就blabla的,猜不对的话就fail。源码:https://paste.ubuntu.com/p/mR4ZCT4t2k/
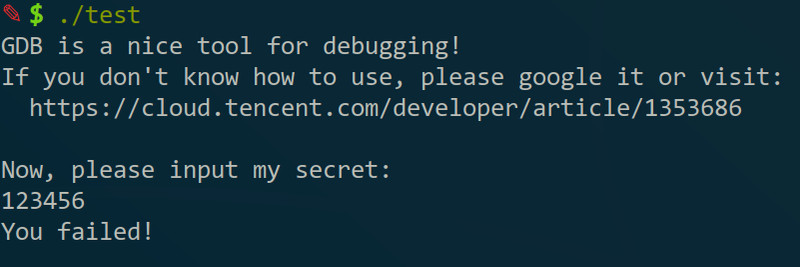
第一个命令是run(缩写“r”),作用是运行程序,可以看出跟直接运行程序没什么差别:
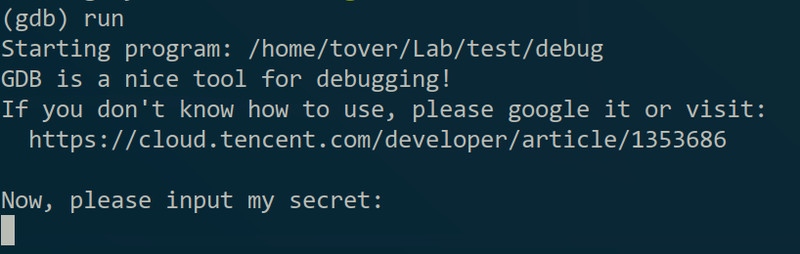
这时按一下“Ctrl+C”的话可以中断程序的执行,注意是中断,如果不是用gdb运行程序的话就是终止程序,大概就是上面说的int 3的操作。这是就可以进行一些调试了,但因为这时是执行到一个叫read的函数,我没有read函数的debug_info,不好说明,所以就放在后面再讲。然后如果想程序继续运行的话可以用continue命令(缩写”c“):
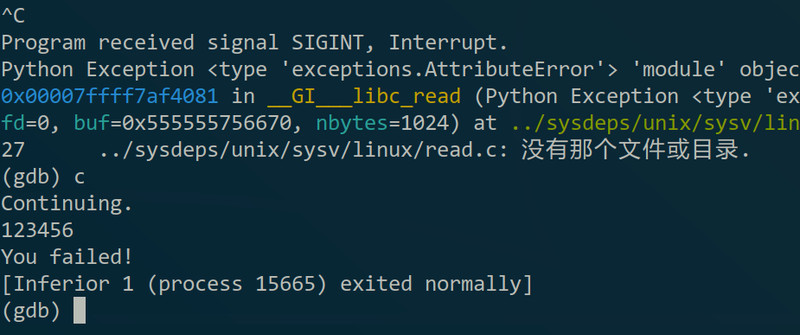
可以看到程序正常退出了,但是我并没有调试到什么。。。这是因为run的方式不对。再来一次,这次在run之前先用break命令(缩写”b“)下个断点,断点就是我想程序运行到哪个地方停止,用法是”break 函数名/行号/地址“,如果想知道break的更详细用法的话可以用”help break“查看(其他命令也是,”help 命令名“就会有用法和介绍)。比如我想程序运行到main函数就停下来了,可以:
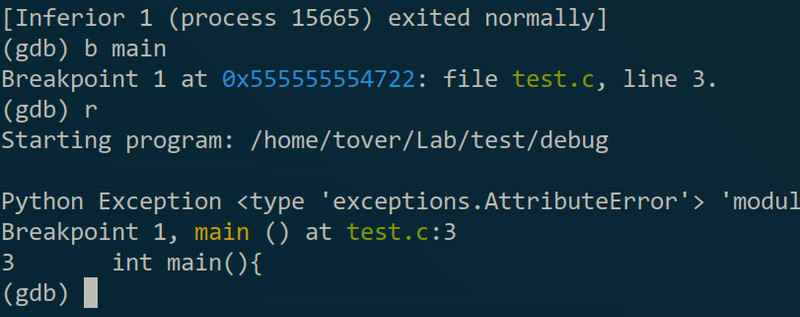
可以看到程序在main里暂停了,证据是它给出了main在源码中的那一行。如果想继续执行的话可以输”continue“,但这样好像并没什么用,所以就需要”next“(缩写”n“):
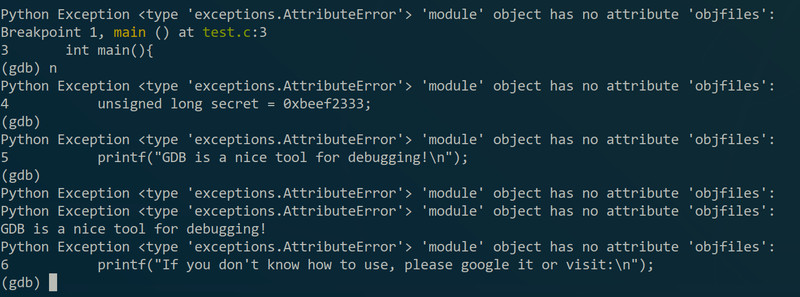
(Python报错那些可以忽略,是我电脑上出了点问题而已- -)然后就看到gdb把下面行的代码都给出来了(给出来的其实是将要执行的代码),注意到有的我是直接输回车的,直接回车代表的是执行上一条命令。另外,如果想看源码的话可以用”list“(缩写”l“):
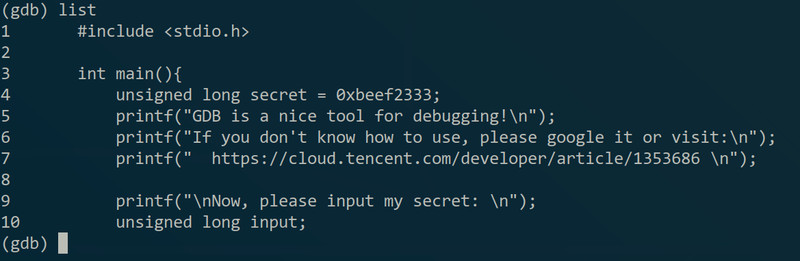
(答案基本就出来了- -)还有要提一下的是”next“命令遇到函数是不会进去的,如果想进入函数的话需要用”step“命令(缩写”s“),想快速执行完当前函数的话可以用”finish“(缩写”fin“)。如果运行到某个地方想知道变量的值的话可以用”print“命令(缩写”p“),比如我想知道secret的值(答案),可以:
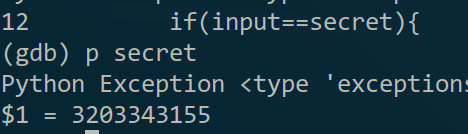
另外介绍个技巧,如果用”list“看代码太麻烦的话可以试一下”layout src“,会随着你执行的位置动态的变化,而且会指出当前位置和断点位置等,退出的话可以按”Ctrl+X+A“:
(入门篇大概就这么多了,主要是要记一下命令,这里也无法列出所有的命令,最好是Google边查边学)
中阶用法
建议掌握初阶用法后再看中阶用法,而且会涉及汇编(大佬的话忽视这句)
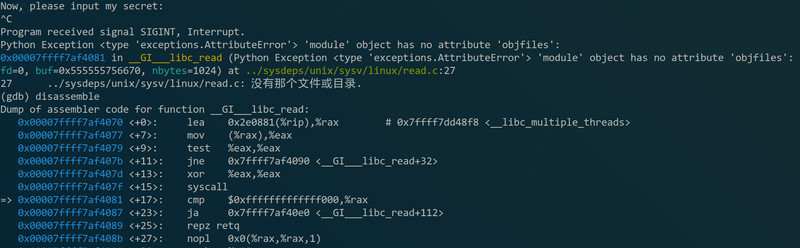
上面也说了,没有debug_info或者没有源码(source)的话就不能像上面那样看着源码调试了,就要在汇编层面上调试了。比如上面”Ctrl+C“后停留在read函数里,而我没有read的debug_info,这个时候可以用”disassemble“命令,从汇编层面查看read的内容:
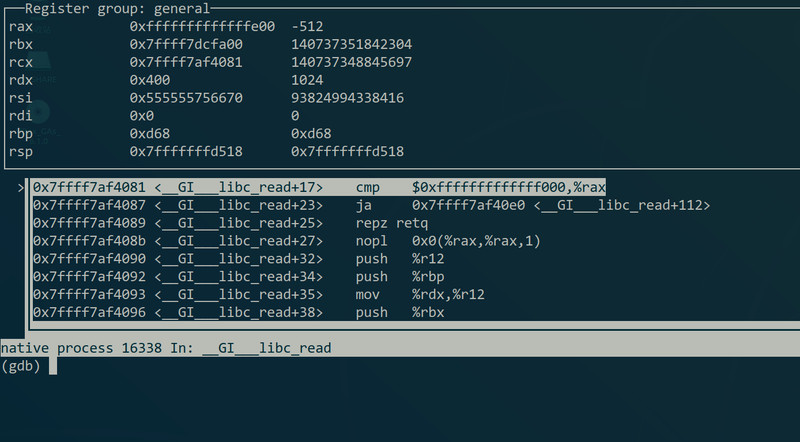
同样可以像”layout src“那样,用”lay asm“命令动态看汇编,或者”lay reg“同时看汇编和寄存器:
但其实最方便的还是直接用插件,比如我在用的Pwndgb,照着github的README安装就好了:
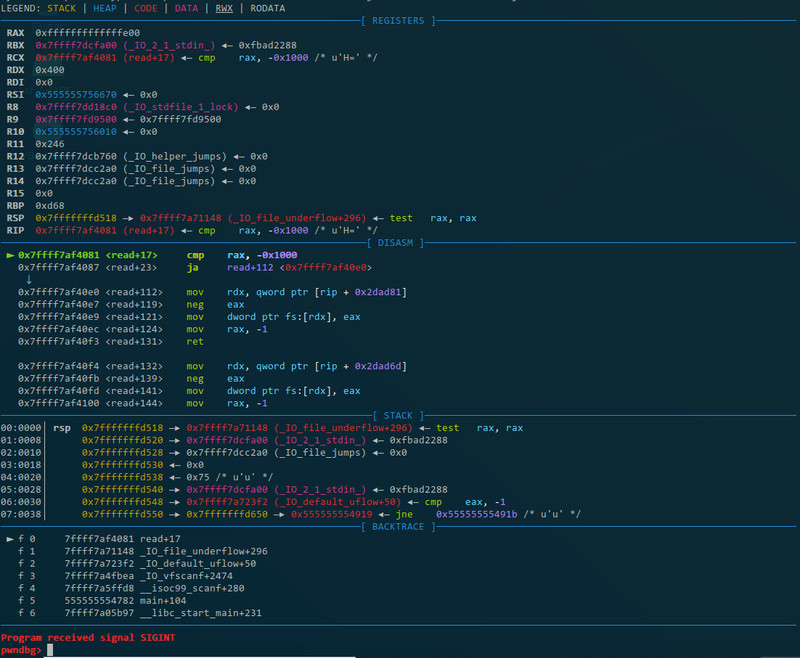
可以看到寄存器、汇编、堆栈、函数栈都有了,还给了语法高亮。然后下面就说一下怎么用gdb+插件来演示一下上面的题怎么做,然后顺便写一下一些常用的命令:
首先在main里下个断点,然后run,虽然程序是没有debug_info,但函数名字这些符号还是有的(而且像libc那些需要做链接的好像也不能没有),所以还是可以用”b main“来下断点,然后就断在了“main+4”的位置,那个”+4“指的是汇编指令(或者说机器码)相对于main函数有多少个字节的偏移。然后也可以单步运行,上面说过单行源码执行是用”next“,而单行汇编执行是用”nexti“(缩写”ni“),而跳进函数是”stepi“(缩写”si“)。
输几个”ni“后执行到”call puts@plt“的地方,”call“其实是指调用函数(现场汇编从入门到劝退),而”puts“是函数名,”@plt“指的是一个叫.plt表的东西,有兴趣可以google(可以”si“进去看一下,应该会发现第一次的”call puts“和第二次之后过程是不一样的)。然后图中的”call puts@plt“下一行是”s: 0x555555554858 ...“,这个就是执行puts函数时的参数,这时看一下寄存器的话会发现其实就是寄存器rdi的值,因为64位程序是fastcall的,call时的参数从左到右分别是rdi、rsi、rdx、rcx、r8、r9(题外话)。然后仔细看一下也会发现其实里面的内容是第一个printf的内容,原因是gcc在编译时会对参数的字符串没有解析(”%i“之类的)的printf优化为puts,加快运行速度。
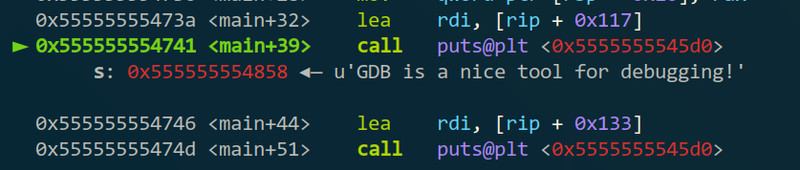
继续一直”ni“后会到一个”call __isoc99_scanf@plt“的地方,这个就是做输入的scanf函数了,可以看到参数有两个,format就是解析的格式(用过scanf的应该都知道了),vararg的就是做scanf后读入的东西放到的地址(先记一下这个地址,可以看到是个栈上的地址,什么是栈的话这里也先不多说了)。
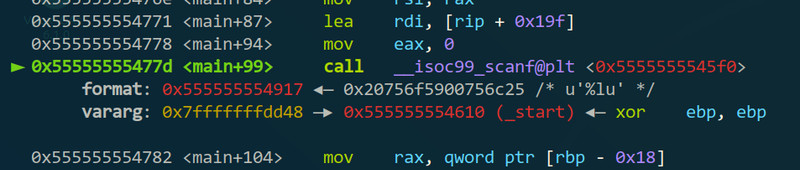
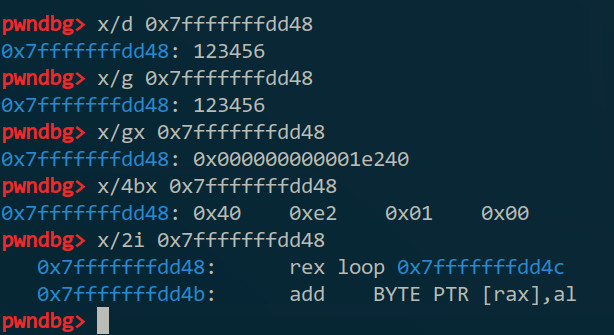
再一个”ni“后会停下来等待输入,输完后才继续执行(比如我输了”123456“),然后在继续追下去之前先看一下读进了什么东西,可以用”x“命令,”x”命令用法是“x 地址”,然后就可以读出地址里面的内容,根据内容解析成的格式不同,“x”命令也有很多变种,“x/d”是把输出的当作有符号整数处理,“x/u”是无符号整数,“x/s”是字符串(这些都跟printf的是差不多的),”x/bx“是一个字节的16进制,”x/wx“是一个字的16进制,”x/x“是32位16进制,”x/gx“是64位16进制,”x/i“是当作指令;也可以输出多个,比如”x/4b“是输出4个字节的16进制,”x/10i“输出往下的10条指令。(我试过的时候发现”x/d“的话好像收上一次的”x/b“或”x/x“等影响的,直接用”x/b“、”x/w“、”x/x“、”x/g“可能会更好)(另外从”x/4b“可以看出我电脑是小端方式存储的)
另外有个很好用的命令叫”hexdump“,可以直接看十六进制和对应字串:

然后上面那些命令应该是够用来做那道题的了,首先因为是猜secret的内容,所以一般来说会在做完scanf后会有一个比较的动作,如果比较出我输入的值跟secret相等的话就blabla,不等的话就fail,比较的话一般是cmp指令(其实scanf后剩下的操作也不多了,要分析也不难,前提是看得懂汇编),所以只要找到cmp指令,然后看一下cmp指令的参数就好了。刚好scanf后的第二句就是cmp:

cmp的两个参数都涉及寄存器,同样用”print“指令可以查看内容,”x“指令可以看寄存器存的地址上的内容,但这个是寄存器,寄存器要输出的话要在前面加个”$“,比如:
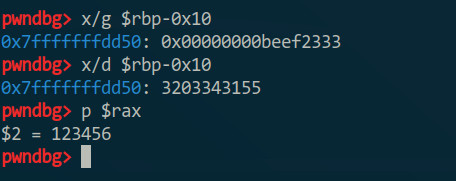
然后答案就是3203343155了,十六进制的0xbeef2333。
然后之前在[科普] 那些放在不同位置的字符串说过字符串会放在栈、堆、.data、.bss等位置,这里也说一下这个怎么看的。首先先”vmmap“一下,作用是查看程序的内存分布,可以看到程序被分成几段,对应放在内存什么位置:
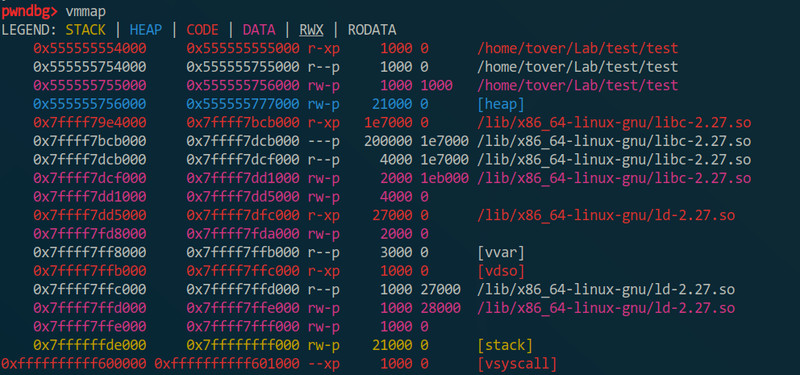
”[heap]“就是堆了,”[stack]“就是栈了,而.data的话是在”0x555555554000“那一段的某个位置(喂,超纲了),因为我搜索含”GDB“的字符串时搜到了那个段,.bss在”0x555555755000“那段的某个位置,因为.bss一般是可写的。可以看到pwndbg其实会对不同段的数据有不同颜色显示的。另外说一下搜索字符串的话可以用”search 字符串“:

后面那两个也不多说了(跟程序的结构有关),栈的话其实pwndbg中每次”next“中都可以看到了,要独立看的话也可以用”stack“命令,想看多点的话可以输”stack 行数“;堆的话有个命令叫”heap“
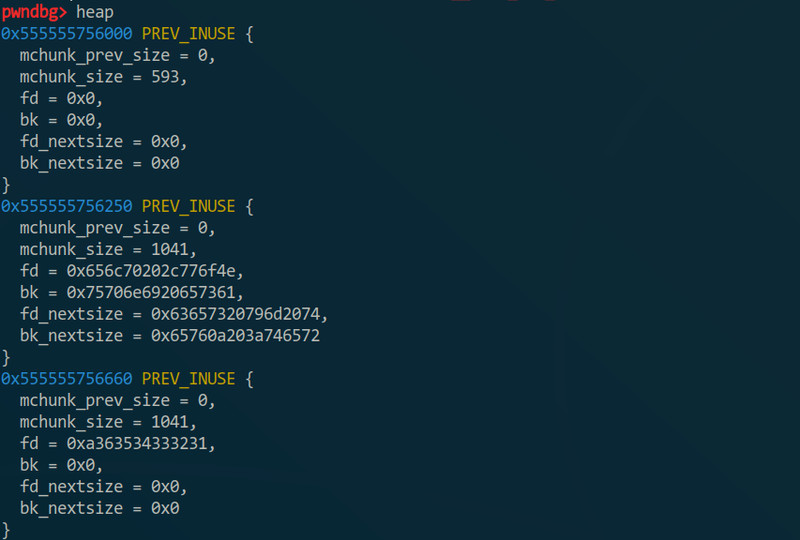
结合”hexdump“可以看一下堆块里的内容,”p (struct malloc_chunk) 地址“可以打印出堆块结构(会堆结构的话应该看得懂不说了,超纲了)
高阶用法
这里主要整理一下GDB中一些有用但挺少见的tricks(不一定很难才是高阶- -)。
GDB Python:GDB的Python接口,可以自己新建一些新的指令,参考https://segmentfault.com/a/1190000005718889
GDB调试libc:很久以前水的一篇
执行”attach 程序pid号“可以attach进正在运行的程序里调试,需要先往”/proc/sys/kernel/yama/ptrace_scope“里写0:
echo 0 | tee /proc/sys/kernel/yama/ptrace_scope
查看errno:”p *__errno_location()“
Docker中用GDB:需要开ptrace,参考 https://blog.csdn.net/snipercai/article/details/80408569
查看结构体定义”ptype 结构体“,查看宏定义”macro 宏“
修改内存内容:”set“命令,”set 地址/变量名 = 数值“,修改寄存器同样,”set $寄存器 = 数值“,参考 https://cloud.tencent.com/developer/ask/114818
GDB带参数(arg)调试:”set arg“,参考 https://www.cnblogs.com/pengdonglin137/articles/5096672.html
pwntools:超纲了,http://docs.pwntools.com/en/stable/gdb.html
服务器的tty中pwntools用tmux启动GDB时设置窗口位置,参考:http://brieflyx.me/2015/python-module/pwntools-advanced/
context.terminal = ['tmux', 'splitw', '-h']
context.terminal = ['tmux', 'splitw', '-v']
结合qemu调试内核:qemu启动加”-s“参数,gdb中”target remote:1234“
dump内存:脱壳常用?”dump memory 存的文件路径 开始位置 结束位置“,参考 https://blog.csdn.net/qq_36119192/article/details/96474833
设置搜索源码的路径:”dir“命令,参考 https://blog.csdn.net/CaspianSea/article/details/42447203
把GDB的输出存到文件:”set logging“输出很多的时候适用,https://blog.csdn.net/jinzhuojun/article/details/7419479
非常全的GDB手册(英文):https://sourceware.org/gdb/onlinedocs/gdb/
结语
以上
好好学习,天天向上
(瞎写勿喷)