
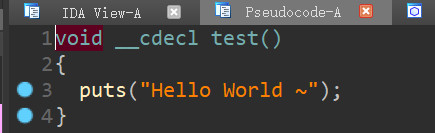
所谓IDA就是那个有很强大 反编译 功能的软件,比如说我有个打印”Hello World“的代码:

编译好后把可执行程序(那个用编辑器打开是乱码的二进制文件)扔进IDA后就可以看出大概的源码:
而混淆IDA就是指在程序里加某些东西,使得IDA反编译后看不出源码是什么,但是程序依然可以正常运行。
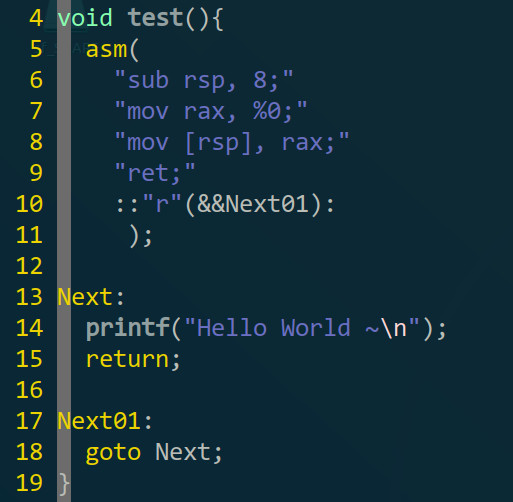
之前也在aaaddress1的这篇文章里看到过一些IDA混淆的方法,但是自己实现了一遍也发现了有些问题,那篇文章是2015年的了,而现在0202年的IDA也升级了不少(这篇帖子测得是7.2版),还有里面的汇编是32位的windows上的汇编,比如当中的一个例子:
编译后看一下test函数:
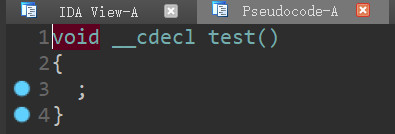
看起来好像是把所有东西都隐藏了,但是在函数列表里却发现了这样一个函数:
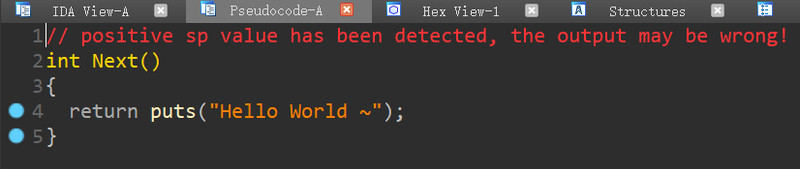
IDA把”Next“这个label当作函数了,虽然test函数里看不到任何东西,但在Next里几乎没有任何的混淆。
所以就自己按照类似的思路写了一种新的(如有雷同,纯属巧合)混淆方法。
混淆
(写了有几个版本,思路是一样的,只是实现上有点不同)
先说下思路,
- 首先IDA的反编译是静态分析的,如果可以利用好运行时才能确定的变量(比如全局变量、各个寄存器特别是rip)的话就可以有效地破坏IDA的静态分析。比如进入函数时不执行真正的指令,而是用运行时的rip算出真正指令的地址做跳转;另外实际操作中发现把地址放在函数参数或者全局变量中也有很好的效果。
- IDA这类反编译软件对常见的汇编代码的反编译效果会好很多,但如果是不常见的代码的话就会较差甚至译不出来,比如aaaddress1说的把”push rax“改成”sub rsp, 8; mov [rsp], rax“。
- 另外,混淆的时候还要注意编译器的优化,有时如果跳转得太离谱的话编译器有可能会把实际代码优化掉,还有要想不破坏正常功能的话实现混淆时要尽量避免常用的寄存器,比如rdi。
例子:
exp1:https://paste.ubuntu.com/p/jzRygv3DtZ/
首先设置了两个全局变量(上面也说了,全局变量有挺好的混淆效果)。”on“是一个标记,一会再讲;”addr“用来存放函数的基址,利用这个基址来计算实际代码的地址,因为直接用函数指针的话反编译后还是挺明显的,所以就用了全局变量做混淆。
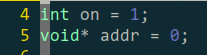
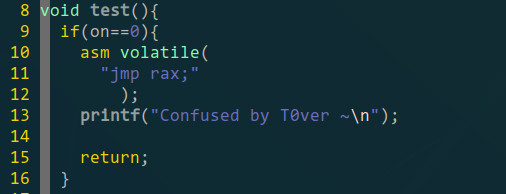
进入函数后先不执行实际代码,首先是个if条件,由于”on“永远是1,所以这个if永远也不会进去,这样做的目的是让编译器不对里面的实际代码做优化(当初是想搞出一种通用的方法才想到这样做的,所谓通用就是实际的代码放到这个if条件里就好了,其他的东西都只是个壳);if条件里的那个内联汇编作用是阻断IDA对后面代码的分析,IDA会认为程序跳转到rax后就不会再跳回来了(实际上也是这样,因为rax里面是什么我也不知道hhhh)。
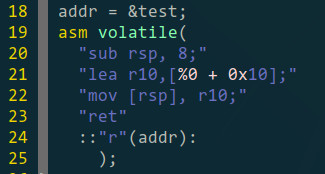
跳过if后接下来就是跳转回if条件里,但是要绕过那个jmp。方法是用test的函数指针来计算出实际代码(就是printf那句)的地址,然后跳转(抄了aaaddress1的return的方法),可能要注意一下的是寄存器用了r10,因为r10是caller saved,大概不会这么常用把(应该- -)。
最后当然是可以运行的:

IDA的混淆效果好像也不错,已经看不到实际代码了:


另外还有两份代码,写得好像相对没这么好的,思路是一样的:
exp2:https://paste.ubuntu.com/p/64Wft86Cpx/
exp3:https://paste.ubuntu.com/p/P63MsNj54D/
反混淆
其实这种混淆方式只能对那些不懂汇编或汇编基础不好的人起作用,虽然反编译结果中没有实际代码,但其实汇编中还是能看出来的,要反混淆的话也只用patch一下就好了。(真正要混淆的话还是需要花指令,虚拟机之类的东西,逃)
